论文题目: Self-supervision with Superpixels:Training Few-Shot Medical Image Segmentation Without Annotation
作者: Cheng Ouyang, Carlo Bi, Chen Chen, Turkay Kart, Huaqi Qiu, Daniel Rueckert
研究机构: BioMedIA Group, Department of Computing, Imperial College London, UK
时间: 2020.01.20
摘要
本文提出了一种用于医学图像的新型自监督 FSS 框架以及Adaptive local prototype pooling模块。解决了few-shot segmentation领域中依赖大量带注释的样本以及通常使用prototype learning的网络架构中存在局部信息丢失的问题,同时解决医学图像分割中常见的具有挑战性的前景-背景不平衡问题。
研究背景
医学图像分割领域存在问题
- 缺少大量的专家注释
- 可能的分割目标(不同的解剖结构、不同类型的病变等)的数量是无数的。 通过训练一个新的、特定的模型来覆盖每一个看不见的类是不切实际的。
Few-shot learning 能够解决上述问题
- Few-shot学习模型在inference阶段仅从少数标记示例(Support set)中提取未见类的判别表示,以对未标记示例(Query set)进行预测,而无需重新训练模型。如果将小样本学习应用于医学图像,则可以仅使用少数标记示例就可以有效地分割罕见或新颖的病变。
Few-shot 语义分割存在问题
- 大多数Few-shot segmentation(FSS)的方法依赖于大量带注释的样本。
- 许多最先进的 FSS 网络架构学习的表示存在局部信息丢失的问题。这个问题在医学图像中尤为突出,因为医学图像中普遍存在极端的前景-背景不平衡。
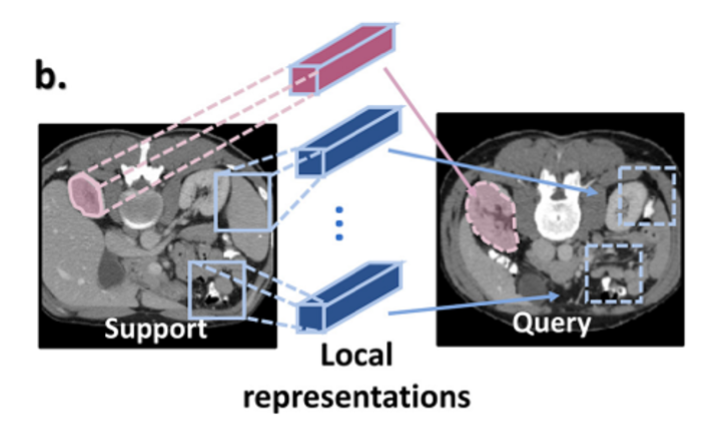
贡献点
- 一种用于医学图像的新型自监督 FSS 框架,以消除训练过程中对注释的需求。 此外,生成基于超像素的伪标签以提供监督;
- 插入Adaptive local prototype pooling模块,解决医学图像分割中常见的具有挑战性的前景-背景不平衡问题;
- 使用三种不同的任务证明了所提出的方法对医学图像的一般适用性:CT和MRI的腹部器官分割,以及 MRI 的心脏分割。对于医学图像分割,所提出的方法优于需要手动注释进行训练的传统FSS方法。
模型框架
模型包括三个部分:特征提取器、Adaptive local prototype pooling以及基于相似性的分类器。
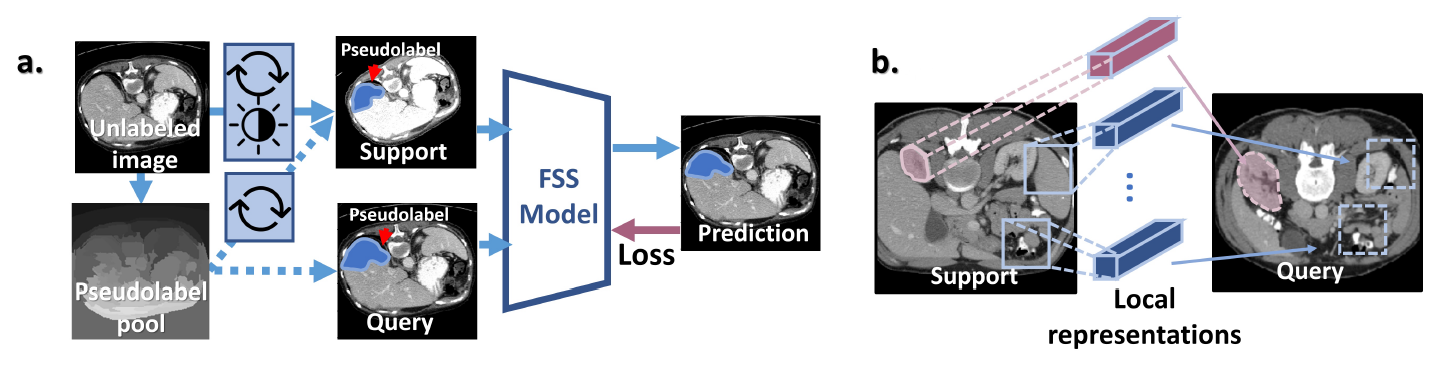
Workflow
- 特征提取器f将support image和query image作为输入,生成对应的feature map
- Adaptive local prototype pooling模块将Support feature map和label作为输入,以获得表示背景和前景的prototype集合。
- 这些prototype用作与Query feature map进行相似性计算,将相似的融合在一起形成最终的分割结果。
Adaptive local prototype pooling
-
模块主要作用: 保护局部信息,在 ALP 中,每个local prototype仅在覆盖在支持上的局部池窗口内计算,并且仅代表感兴趣目标的一部分。
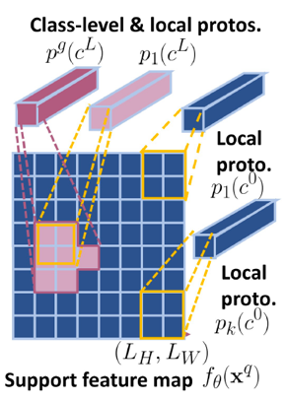
-
local prototype的计算方法
- 选择feature map上 \((L_H, L_W)\) 进行平均池化
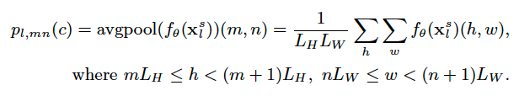
- 为了确定每个位置是前景还是背景,对label的前景mask也进行相同范围的平均池化,当阈值T>0.95时为前景类,否则为背景:
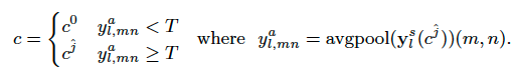
- 为了确保为小于池化窗口(LH,LW)的分割目标生成至少一个Prototype,计算一个class-level的prototype通过masked平均池化:
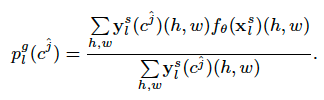
通过将不同的局部区域明确表示为单独的prototype来保留更多的类内局部区别
Similarity-based segmentation
- 基于相似度的分类器旨在通过利用local prototype和class-level中的信息对Query进行密集预测。这是通过首先将每个prototype与query中的相应局部区域匹配,然后将局部相似性融合在一起来实现的。
Superpixel-based Self-supervised Learning
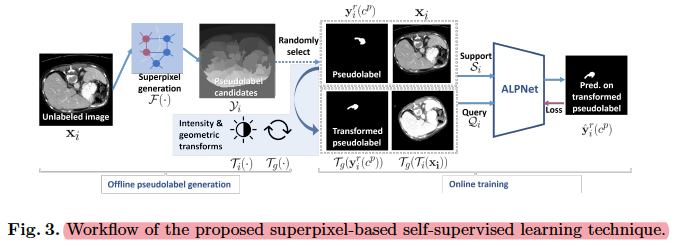
- Motivation:为了获得准确和稳健的结果,基于相似性的分类器非常需要两个属性。对于每个类,表示应该进行聚类,以便在相似性度量下具有区分性;同时,这些表示在图像之间应该是不变的以确保预测的鲁棒性。
- 所提出的基于超像素的自监督学习 (SSL) 鼓励了这两个属性。SSL框架主要包含两部分,第一部分是伪标签生成,利用超像素算法对像素进行聚类,随机在超像素map上选择一个强度值作为伪标签,因此,超像素级的聚类属性可以转移到真正的语义类中,因为一个语义掩码通常由几个超像素组成。
- 第二部分,为了鼓励表示对图像之间的形状和强度差异保持不变,在support和query之间进行几何和强度转换,这是因为形状和强度是医学图像变化的最大来源。
实验
数据集
- Abd-CT:MICCAI 2015 Multi-Atlas Abdomen Labeling challenge. 包含30个3D abdominal CT scans.临床数据集,其中包含具有各种病理和扫描之间强度分布变化的患者。
- Abd-MRI: ISBI 2019 Combined Healthy Abdominal Organ Segmentation Challenge. 包含20个3D T2-SPIR MRI scans.
- Card-MRI: MICCAI 2019 Multi-sequence Cardiac MRI Segmentation Challenge.包含35个临床 3D cardiac MRI scans.
对比实验
- setting 1:测试类可能作为训练背景出现数据
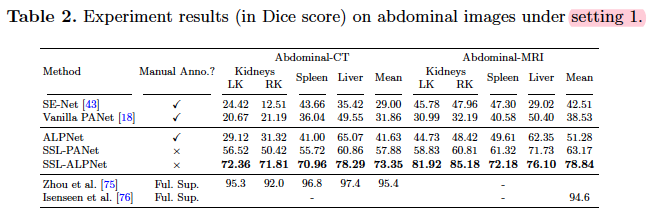
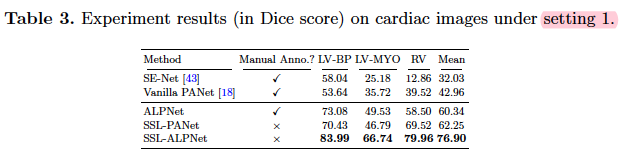
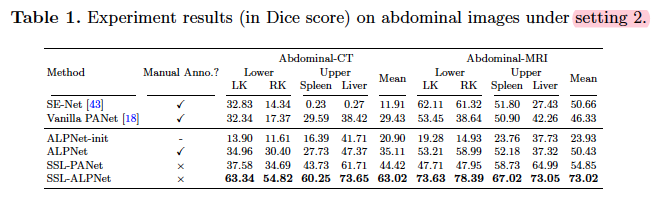
- setting 2:通过从训练数据集中删除任何包含测试类的图像来强制测试类完全不可见
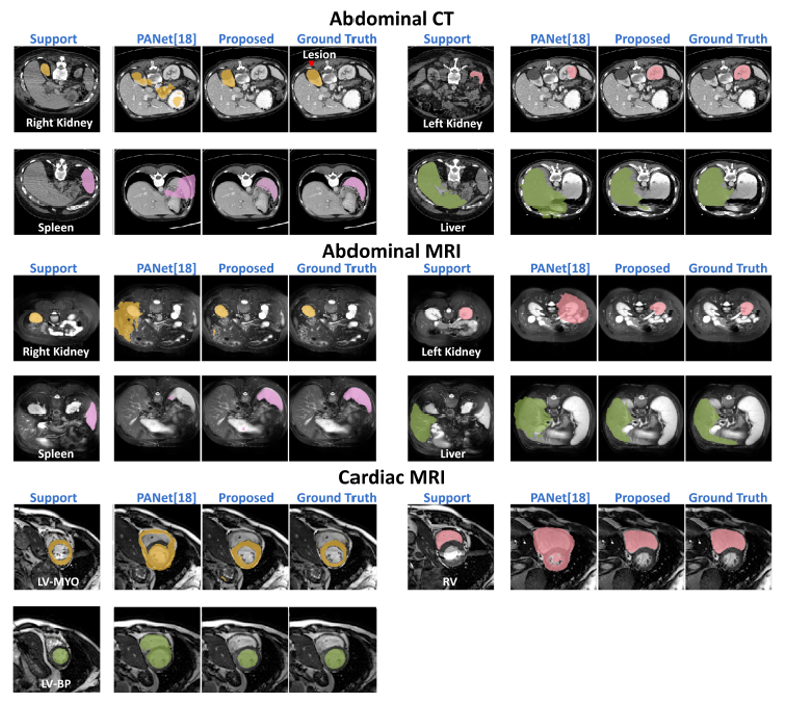
启发
- 医学图像存在极端的前景背景不平衡问题,本篇文章结合local prototype和class-level prototype解决这个问题。这种提取多个prototype的方法虽然比只提取前景和背景的prototype保留的信息更多,但是还存在一定的信息丢失问题。
- 文中提出的SSL自监督策略,大幅度提高了结果,分析原因:其打破了原有的提取伪标签的方法,利用超像素聚类来随机提取伪标签,从而让模型见识到了多种多样的结构,这种结构同时都带有有一定的语义信息,再加上几何和对比度的增强,让模型更加鲁棒,学习到了分割的能力。
- 从这篇文章可以得到两种解决问题的方法
- 一是不管是前景还是背景都存在有用的信息,因此可以在feature map的层次进行逐像素的判断此特征是否对分割有用。
- 二是让模型在训练的过程中尽可能见到多种多样的样本,泛化能力才能更好,才能更好的分割没见过的类,同时还可以利用一致性的约束,更加利于模型学习不变的特征。