论文题目: Adaptive Prototype Learning and Allocation for Few-Shot Segmentation
作者: Gen Li, Varun Jampani, Laura Sevilla-Lara, Deqing Sun, Jonghyun Kim, Joongkyu Kim
研究机构: University of Edinburgh Google Research Sungkyunkwan University
摘要
本文提出了自适应超像素引导网络(ASGNet),这是一种灵活的prototype learning方法,适用于少样本分割,可适应不同的对象尺度、形状和遮挡。ASGNet以更少的参数和更少的计算实现了性能最佳的结果。
研究背景
- 现在大部分few-shot分割都是通过提取Prototype features来实现的,虽然Prototype的优点比单独用pixel对噪声不敏感,更加具有鲁棒性。但是当support和query之间的物体外观有较大变化时,prototype又会损失空间信息,同时仅仅生成单一的prototype也会丢失有用的信息。
贡献点
- 提出了自适应超像素引导网络(ASGNet),这是一种灵活的原型学习方法,适用于少样本分割,可适应不同的对象尺度、形状和遮挡。
- 引入了两个新模块,即超像素引导聚类(SGC)和引导原型分配(GPA),分别用于自适应原型提取和分配。它们可以作为特征匹配的有效即插即用组件。
- ASGNet以更少的参数和更少的计算实现了性能最佳的结果。具体来说,所提出的方法在 Pascal-5i/COCO-20i 上的5-shot设置中获得了64.36%/42.48%的mIoU,超过了现有技术2.40%/5.08%。
补充知识: 超像素算法
SLIC算法(simple linear iterative clustering)
将彩色图像转化为CIELAB颜色空间和XY坐标下的5维特征向量,然后对5维特征向量构造距离度量标准,对图像像素进行局部聚类的过程。SLIC算法能生成紧凑、近似均匀的超像素。
- 初始化种子点(聚类中心):按照设定的超像素个数,在图像内均匀的分配种子点。假设图片总共有N个像素点,预分割为K个相同尺寸的超像素,那么每个超像素的大小为N/K,则相邻种子点的距离(步长)近似为S=sqrt(N/K)。
- 在种子点的n*n邻域内重新选择种子点。具体方法为:计算该邻域内所有像素点的梯度值,将种子点移到该邻域内梯度最小的地方。
- 在每个种子点周围的邻域内为每个像素点分配类标签(即属于哪个聚类中心)。
- 距离度量。包括颜色距离和空间距离。对于每个搜索到的像素点,分别计算它和该种子点的距离。距离计算方法如下:
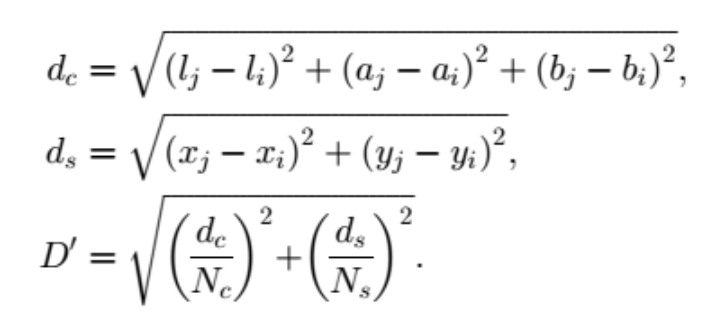
dc代表颜色距离,ds代表空间距离,Ns是类内最大空间距离,定义为Ns=S=sqrt(N/K),适用于每个聚类。
- 迭代优化。理论上上述步骤不断迭代直到误差收敛(可以理解为每个像素点聚类中心不再发生变化为止),实践发现10次迭代对绝大部分图片都可以得到较理想效果,所以一般迭代次数取10。
- 增强连通性。经过上述迭代优化可能出现以下瑕疵:出现多连通情况、超像素尺寸过小,单个超像素被切割成多个不连续超像素等,这些情况可以通过增强连通性解决。
模型框架
Overall structure
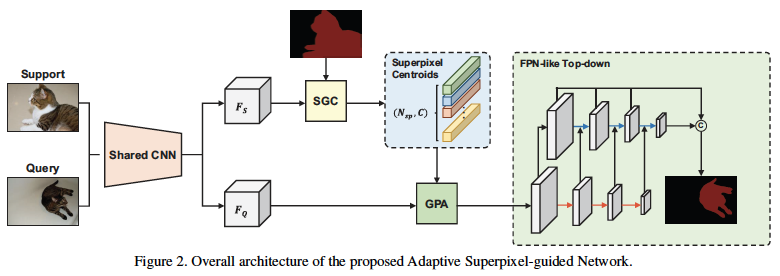
- 首先,将support和query image输入共享的CNN(在ImageNet上进行预训练)以提取特征。然后,通过SGC传递Support特征,获得超像素质心,这些质心被视prototype。之后,为了更准确的逐像素引导,采用GPA模块将prototype与query特征进行匹配。最后,建立FPNlike自上而下的结构来引入多尺度信息,将特征从精细转移到粗糙促进了特征交互,因此我们遵循他们的设计进行快速多尺度聚合。最后,所有不同的尺度被连接起来,每个尺度产生一个分割结果来计算损失。
Superpixel-guided Clustering(SGC)
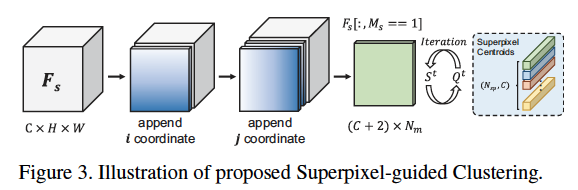
- 通过superpixel simple network(SSN)和MaskSLIC得到启发。用聚类的方式将feature map聚合成多个superpixel质心作为prototype。SGC算法如下:

-
首先,将每个像素的坐标与support feature map连接起来,引入位置信息。然后定义距离函数D
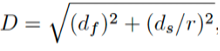
其中df和ds分别代表特征和空间的距离。
-
然后过滤掉背景,提取前景的feature map。以迭代方式计算基于superpixel的prototype。对于每个迭代t,首先根据距离函数D计算每个像素p和所有superpixel之间的关联映射Qt:
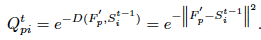
-
新的超像素质心被更新为加权的Mask特征之和:
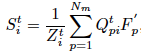
Guided Prototype Allocation(GPA)
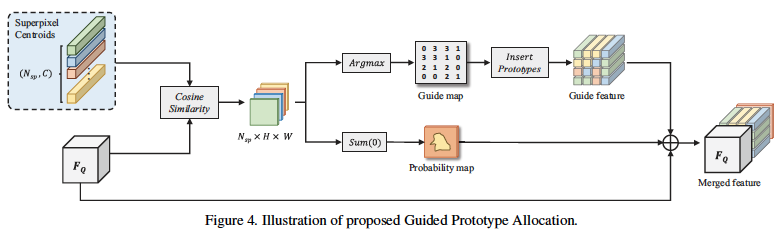
- 为了使prototype能够更自适应的匹配query image,提出了GPA模块。首先计算每个prototype和query feature的余弦相似度。将相似度信息分别做为后面两个分支的输入,第一个分支计算,在每个像素位置,哪个prototype最相似,得到guide map G。
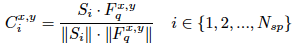
另一个分支,所有的相似性信息C在所有超像素上相加得到概率图P。最后,将这些信息concatenate组成FQ。
Adaptability
-
在SGC中,为了使其适应对象尺度,定义了一个标准来调节超像素质心的数量为:
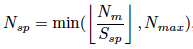
Nm是support mask的pixels数量,Ssp是分配给每个初始超像素种子的平均面积,根据经验设置为100。当前景很小时,方法退化为平均池化。在GPA中,可以观察到它对物体形状的适应性。当查询图像中存在严重遮挡时,GPA可以为每个查询特征位置选择最匹配的原型。
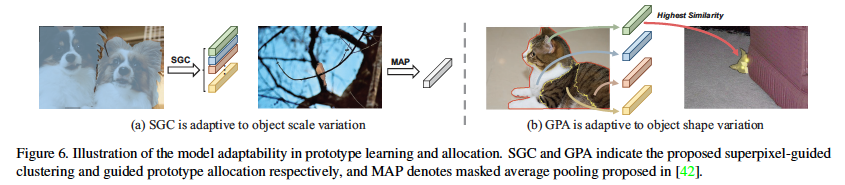
实验
数据集
- Pascal-5:The total 20 categories are evenly partitioned into four splits, and the model training is conducted in a crossvalidation manner.
- COCO-20: 82,081 images in the training set. the overall 80 classes from MSCOCO are evenly divided into four splits with the same cross-validation strategy.
对比实验
- 定量结果
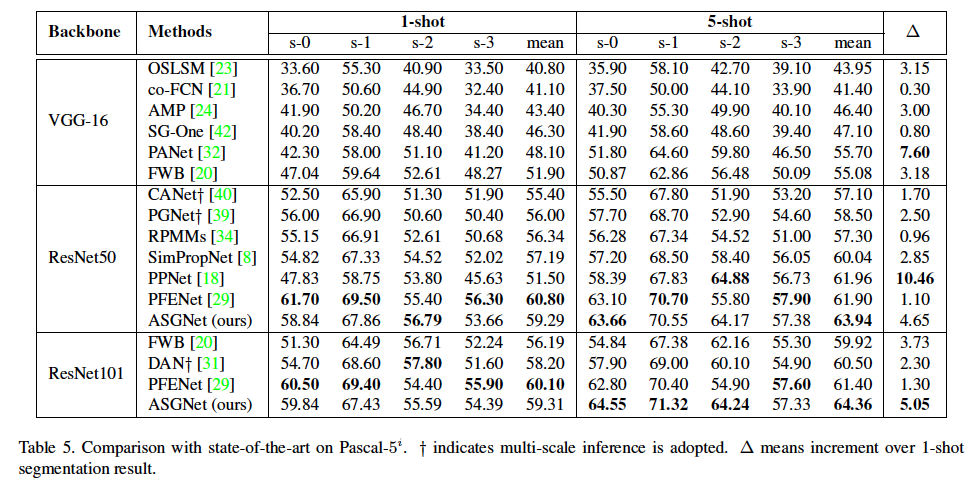
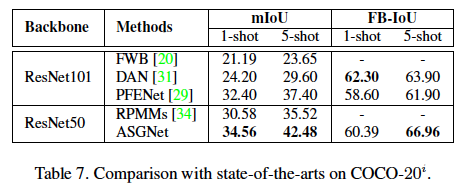
- 定性结果

启发
- 与以往用平均池化提取prototype的方式不同,本篇文章利用超像素聚类的方式提取prototype,同时引入了位置信息。能够很好的保留信息。但其依然只对前景进行prototype的提取,忽略了背景信息,已有文献证明背景中的部分信息也同样有助于分割。
- 本文提出了GPA的框架来自适应的分配prototype,这种自适应的方式值得借鉴和思考。因为对于不同图像,所需要的有用信息是不同的,所以自适应的选择prototype是一个好的策略。