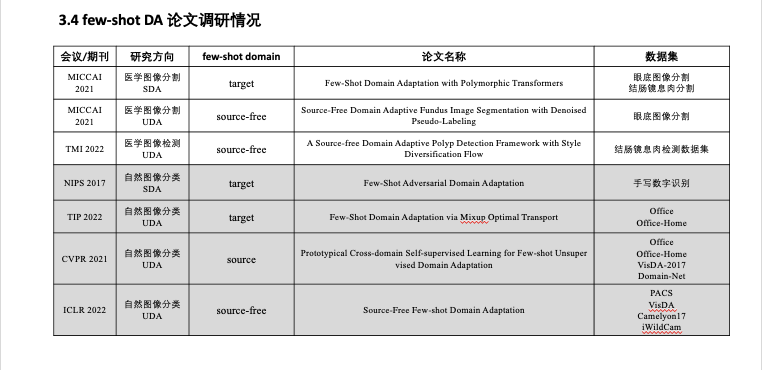
- (NIPS 2017)Few-Shot Adversarial Domain Adaptation
- (MICCAI 2021)Few-Shot Domain Adaptation with Polymorphic Transformers
- (TIP 2022)Few-Shot Domain Adaptation via Mixup Optimal Transport
- (CVPR 2021)Prototypical Cross-domain Self-supervised Learning for Few-shot Unsupervised Domain Adaptation
- Few-shot DA 论文调研情况
(NIPS 2017)Few-Shot Adversarial Domain Adaptation
研究方向
- Supervised domain adaptation
- 自然图像分类
解决问题
- 当target domain只有少量样本有label时,由于缺乏数据,因此对齐或分离语义概率分布是很困难的
研究意义
-
研究Domain adaptation的意义
深度学习方法通常依赖于大规模带有标签的数据集,然而其收集和注释成本高。通常,在这种情况下,从业者将从具有大量样本的密切相关数据集(源域)中训练或重用模型,然后使用更小的感兴趣数据集(目标域)进行训练,这个过程叫做Finetuning。Finetuning虽然易于实现,但是与domain adaptation相比,它是次优的。
-
研究Few-shot Supervised Domain adaptation的意义
UDA算法不需要任何target data labels,但它们需要大量target training samples。相反,SDA算法确实需要labeled target data,那么对于相同数量的target data,SDA 优于 UDA。 因此,如果可用的target data稀缺,SDA 也很有吸引力,因为只需要标注很少的样本。
研究挑战
- target domain数据量非常小,如何增强
- 如何利用target domain的标签信息
实验setting
- 训练数据
Source domain:全部source domain的带label的训练数据
Target domain:n个labeled target data(n=1…10)
- 测试数据
Target domain的全部测试数据
- 对比方法
无域适应、UDA方法、SDA方法、fine-tuning方法
应用场景
可扩展到医学临床场景,难以获取大量target domain数据的情况下,仅用几个样本就能够实现source domain到target domain的域自适应。
(MICCAI 2021)Few-Shot Domain Adaptation with Polymorphic Transformers
研究方向
- Supervised domain adaptation
- 医学图像分类
解决问题
- 解决缺少带label的目标域数据
研究意义
-
研究缺少Target labeled data few-shot的意义
对于DA问题来说,如果目标域中存在大量带注释的数据,则域适应是微不足道的。 然而,这样的注释通常获取成本很高,尤其是对于分割任务。 获得少量注释仍然便宜且可行。
研究挑战
- target domain数据量小,如何防止过拟合
实验setting
- 训练数据
Source domain:全部source domain的带label的训练数据
Target domain:5个labeled target data
- 测试数据
Target domain的全部测试数据
- 对比方法
无域适应、SDA方法、fine-tuning方法、在两个domain中转换的方法
(TIP 2022)Few-Shot Domain Adaptation via Mixup Optimal Transport
研究方向
- Unsupervised domain adaptation
- 自然图像分类
解决问题
- 长尾分布的域自适应问题
研究意义
-
研究缺少Source labeled data few-shot的意义
-
域适应方法通常基于源域类别均匀分布的假设。然而,不平衡或长尾分布在实际中很常见。某些特定类别的样本可能难以收集和注释,因此某些类别的可访问样本可能有限。例如,糖尿病视网膜病变数据集的每张图像都是在临床检查期间捕获的,并由几位眼科医生组成的小组进行注释。因此,不能保证数据集中的样本是均匀分布的。
-
已经做了一些工作来研究少样本监督域适应问题,但是无监督域适应的少样本设置仍处于探索不足的阶段。对于few-shot无监督域适应问题,目标域中的样本没有任何标签信息,而源域中的样本标记良好但在few-shot设置下。源域中的一些类可能只包含一些训练实例,可以表示为少样本类,其他类是具有足够样本的正常集类。如果在训练过程中直接使用few-shot类和normal-set类的平均误差,可能会导致分类器偏向多数类,对少数类有更高的分类误差。
-
研究挑战
- 与原始的域自适应设置相比,它需要同时解决domain shift和分布不平衡问题。
- 解决此类问题的关键是避免从少数源域学习的分类器偏向于多数类。因为它可能会导致目标域的性能下降。
实验setting
- 训练数据
Source domain:将全部类分为:few-shot classes和normal classes
Target domain:无标签数据
- 测试数据
Target domain的全部测试数据
- 对比方法
Discrepancy-based 方法、Adversarial-based 方法、Generative-based 方法、Few-shot Learning-based 方法
(CVPR 2021)Prototypical Cross-domain Self-supervised Learning for Few-shot Unsupervised Domain Adaptation
研究方向
- Unsupervised domain adaptation
- 自然图像分类
解决问题
- 解决缺少带label的源域数据
研究意义及挑战
-
研究缺少Source labeled data few-shot的意义
在一些实际应用中,由于注释成本高且难度大,即使在源域中提供大规模注释通常也具有挑战性。由于标记源样本数量非常有限,因此在源域中学习判别特征要困难得多,更不用说在目标域中了。
实验setting
- 训练数据
Source domain:n个labeled source data(n=1…10)
Target domain:无label数据
- 测试数据
Target domain的全部测试数据
- 对比方法
SOTA UDA方法、SOTA FUDA方法 (adaptation with few source labels)、和本文中技术相关的DA算法。
应用场景
以医学成像为例,糖尿病视网膜病变数据集的每张图像都由 7 或 8 名美国董事会认证的眼科医生组成的小组进行注释,该小组共有 54 名医生。因此,假设具有丰富标签的源数据的可用性过于严格。
Few-shot DA 论文调研情况